(5) Marginalization 파트 중요 코드 정리
[논문설명 발췌]
In order to bound the computational complexity of our optimization-based VIO, marginalization is incorporated
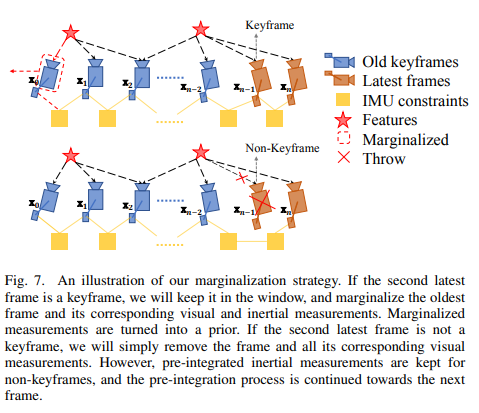
Second-last frame이 keyframe이면 : oldest가 marginalized.
Non-keyframe이면 : visual은 삭제하고 IMU값은 축적한다.
→ Our marginalization scheme aims to keep spatially separated keyframes in the window. This ensures sufficient parallax for feature triangulation, and maximizes the probability of maintaining accelerometer measurements with large excitation. The marginalization is carried out using the Schur complement.
Marginalization result는 early-fix이기 때문에, sub-optimal한 결과를 줄 수도 있으나 이 정도 small drift는 VIO에서 acceptable하다고 한다.
1. Marginalization
1) void Estimator::optimization()
if (last_marginalization_info && last_marginalization_info->valid)
{
// construct new marginlization_factor
MarginalizationFactor *marginalization_factor = new MarginalizationFactor(last_marginalization_info);
problem.AddResidualBlock(marginalization_factor, NULL,
last_marginalization_parameter_blocks);
}
...
if (marginalization_flag == MARGIN_OLD)
options.max_solver_time_in_seconds = SOLVER_TIME * 4.0 / 5.0;
else
options.max_solver_time_in_seconds = SOLVER_TIME;
...
if (marginalization_flag == MARGIN_OLD)
{
MarginalizationInfo *marginalization_info = new MarginalizationInfo();
vector2double();
if (last_marginalization_info && last_marginalization_info->valid)
{
vector<int> drop_set;
for (int i = 0; i < static_cast<int>(last_marginalization_parameter_blocks.size()); i++)
{
if (last_marginalization_parameter_blocks[i] == para_Pose[0] ||
last_marginalization_parameter_blocks[i] == para_SpeedBias[0])
drop_set.push_back(i);
}
// construct new marginlization_factor
MarginalizationFactor *marginalization_factor = new MarginalizationFactor(last_marginalization_info);
ResidualBlockInfo *residual_block_info = new ResidualBlockInfo(marginalization_factor, NULL,
last_marginalization_parameter_blocks,
drop_set);
marginalization_info->addResidualBlockInfo(residual_block_info);
}
if(USE_IMU)
{
if (pre_integrations[1]->sum_dt < 10.0)
{
IMUFactor* imu_factor = new IMUFactor(pre_integrations[1]);
ResidualBlockInfo *residual_block_info = new ResidualBlockInfo(imu_factor, NULL,
vector<double *>{para_Pose[0], para_SpeedBias[0], para_Pose[1], para_SpeedBias[1]},
vector<int>{0, 1});
marginalization_info->addResidualBlockInfo(residual_block_info);
}
}
- 지난 optimization에서 marginalization이 있었다면 optimization factor에 사용된다.
- keyframe인 경우 solve하는 시간이 더 짧다. (Why?)
-
추후 premarginalize(), marginalize()를위한 marginalization_info를 만든다.
이 marginalization_info에 marginalization_factor, imu_factor (0번째 frame과 1번째 frame사이의 값들인 pre_integrations[1]), ProjectionTwoFrameOneCamFactor 등을 ResidualBlockInfo로 만들어 marginalization_info→addResidualBlockInfo로 추가해준다.
- last_marginalization_parameter_blocks[i] 가 para_Pose[0] (address) 와 같은 것은 drop_set으로 넣는다. (keyframe의 경우 addr_shift에서 para_Pose[0]의 address를 넣지 않기때문에 없다. Non-keyframe의 경우 이곳에서 dropset으로 추가함으로써 jacobian,residual 계산에 추가된다. → Accumulation)
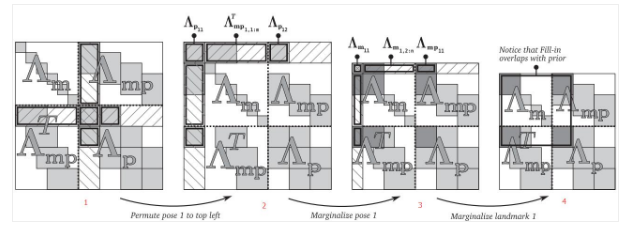
2) void Estimator::optimization()
int feature_index = -1;
for (auto &it_per_id : f_manager.feature)
{
it_per_id.used_num = it_per_id.feature_per_frame.size();
if (it_per_id.used_num < 4)
continue;
++feature_index;
int imu_i = it_per_id.start_frame, imu_j = imu_i - 1;
if (imu_i != 0)
continue;
Vector3d pts_i = it_per_id.feature_per_frame[0].point;
for (auto &it_per_frame : it_per_id.feature_per_frame)
{
imu_j++;
if(imu_i != imu_j)
{
Vector3d pts_j = it_per_frame.point;
ProjectionTwoFrameOneCamFactor *f_td = new ProjectionTwoFrameOneCamFactor(pts_i, pts_j, it_per_id.feature_per_frame[0].velocity, it_per_frame.velocity,
it_per_id.feature_per_frame[0].cur_td, it_per_frame.cur_td);
ResidualBlockInfo *residual_block_info = new ResidualBlockInfo(f_td, loss_function,
vector<double *>{para_Pose[imu_i], para_Pose[imu_j], para_Ex_Pose[0], para_Feature[feature_index], para_Td[0]},
vector<int>{0, 3});
marginalization_info->addResidualBlockInfo(residual_block_info);
}
if(STEREO && it_per_frame.is_stereo)
{
Vector3d pts_j_right = it_per_frame.pointRight;
if(imu_i != imu_j)
{
ProjectionTwoFrameTwoCamFactor *f = new ProjectionTwoFrameTwoCamFactor(pts_i, pts_j_right, it_per_id.feature_per_frame[0].velocity, it_per_frame.velocityRight,
it_per_id.feature_per_frame[0].cur_td, it_per_frame.cur_td);
ResidualBlockInfo *residual_block_info = new ResidualBlockInfo(f, loss_function,
vector<double *>{para_Pose[imu_i], para_Pose[imu_j], para_Ex_Pose[0], para_Ex_Pose[1], para_Feature[feature_index], para_Td[0]},
vector<int>{0, 4});
marginalization_info->addResidualBlockInfo(residual_block_info);
}
else
{
ProjectionOneFrameTwoCamFactor *f = new ProjectionOneFrameTwoCamFactor(pts_i, pts_j_right, it_per_id.feature_per_frame[0].velocity, it_per_frame.velocityRight,
it_per_id.feature_per_frame[0].cur_td, it_per_frame.cur_td);
ResidualBlockInfo *residual_block_info = new ResidualBlockInfo(f, loss_function,
vector<double *>{para_Ex_Pose[0], para_Ex_Pose[1], para_Feature[feature_index], para_Td[0]},
vector<int>{2});
marginalization_info->addResidualBlockInfo(residual_block_info);
}
}
}
}
marginalization_info->preMarginalize();
marginalization_info->marginalize();
std::unordered_map<long, double *> addr_shift;
for (int i = 1; i <= WINDOW_SIZE; i++)
{
addr_shift[reinterpret_cast<long>(para_Pose[i])] = para_Pose[i - 1];
if(USE_IMU)
addr_shift[reinterpret_cast<long>(para_SpeedBias[i])] = para_SpeedBias[i - 1];
}
for (int i = 0; i < NUM_OF_CAM; i++)
addr_shift[reinterpret_cast<long>(para_Ex_Pose[i])] = para_Ex_Pose[i];
addr_shift[reinterpret_cast<long>(para_Td[0])] = para_Td[0];
vector<double *> parameter_blocks = marginalization_info->getParameterBlocks(addr_shift);
if (last_marginalization_info)
delete last_marginalization_info;
last_marginalization_info = marginalization_info;
last_marginalization_parameter_blocks = parameter_blocks;
}
- stereo는 만드는 ResidualBlockInfo도 다르고, drop_set도 다르다.
- preMarginalize(), marginalize() 이후, addr_shift map container에 (key,value) = (i번째 parameter의 주소, i-1번째 parameter의 주소) 를 저장한다. (para_Pose, para_SpeedBias)
para_Ex_Pose, para_Td는 index 차이 없이 동일하게 저장한다.
3) void Estimator::optimization()
else
{
if (last_marginalization_info &&
std::count(std::begin(last_marginalization_parameter_blocks), std::end(last_marginalization_parameter_blocks), para_Pose[WINDOW_SIZE - 1]))
{
MarginalizationInfo *marginalization_info = new MarginalizationInfo();
vector2double();
if (last_marginalization_info && last_marginalization_info->valid)
{
vector<int> drop_set;
for (int i = 0; i < static_cast<int>(last_marginalization_parameter_blocks.size()); i++)
{
ROS_ASSERT(last_marginalization_parameter_blocks[i] != para_SpeedBias[WINDOW_SIZE - 1]);
if (last_marginalization_parameter_blocks[i] == para_Pose[WINDOW_SIZE - 1])
drop_set.push_back(i);
}
// construct new marginlization_factor
MarginalizationFactor *marginalization_factor = new MarginalizationFactor(last_marginalization_info);
ResidualBlockInfo *residual_block_info = new ResidualBlockInfo(marginalization_factor, NULL,
last_marginalization_parameter_blocks,
drop_set);
marginalization_info->addResidualBlockInfo(residual_block_info);
}
marginalization_info->preMarginalize();
marginalization_info->marginalize();
std::unordered_map<long, double *> addr_shift;
for (int i = 0; i <= WINDOW_SIZE; i++)
{
if (i == WINDOW_SIZE - 1)
continue;
else if (i == WINDOW_SIZE)
{
addr_shift[reinterpret_cast<long>(para_Pose[i])] = para_Pose[i - 1];
if(USE_IMU)
addr_shift[reinterpret_cast<long>(para_SpeedBias[i])] = para_SpeedBias[i - 1];
}
else
{
addr_shift[reinterpret_cast<long>(para_Pose[i])] = para_Pose[i];
if(USE_IMU)
addr_shift[reinterpret_cast<long>(para_SpeedBias[i])] = para_SpeedBias[i];
}
}
for (int i = 0; i < NUM_OF_CAM; i++)
addr_shift[reinterpret_cast<long>(para_Ex_Pose[i])] = para_Ex_Pose[i];
addr_shift[reinterpret_cast<long>(para_Td[0])] = para_Td[0];
vector<double *> parameter_blocks = marginalization_info->getParameterBlocks(addr_shift);
if (last_marginalization_info)
delete last_marginalization_info;
last_marginalization_info = marginalization_info;
last_marginalization_parameter_blocks = parameter_blocks;
}
}
-
Non-keyframe의 경우, marginalization_info에 등록하는 ResidualBlockInfo에 marginalization_factor만 추가한다. 또한 marginalization_factor의 drop_set도 WINDOW_SIZE - 1의 주소값과 같은 것만 넣는다.
** 지금 frame이 non-keyframe이고 WINDOW_SIZE-1이 keyframe이면 WINDOW_SIZE-1을 무시하는 것, sliding에서도 동일함.
-
또한 addr_shift에서 i=WINDOW_SIZE, WINDOW_SIZE-1을 제외하고는 (key,value) = (i번째 parameter의 주소, i번째 parameter의 주소) 를 저장한다. i=WINDOW_SIZE-1은 아에 고려하지 않고, i=WINDOW_SIZE에 i-1 = WINDOW_SIZE-1의 parameters를 넣어준다.
2. Several Marginalization factors
[SUMMARY]
-
MarginalizationInfo 생성시에 ResidualBlockInfo 사용, 3개의 factor로 구성.
(MarginalizationFactor, IMUFactor, ProjectionOneFrameTwoCamFactor)
-
Marginalize()로 MarginalizationInfo의 jacobian, residual을 구한다.
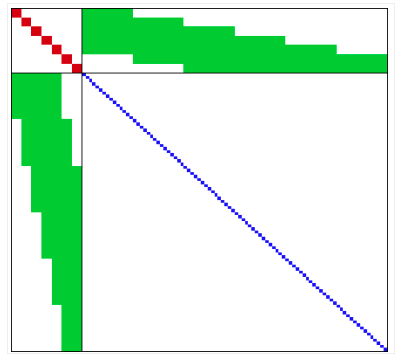
-
IMU constraints to Prior (address를 유지)
우선, vision 관련 feature는 index 변환이 없으므로 addr_shift에서 IMU constraint만 변환 한다. (sliding window에서 frame을 삭제해주기도 한다.)
Keyframe : para_Pose[0, …, WINDOW_SIZE -1] , para_SpeedBias[0, …, WINDOW_SIZE-1] para_Ex_Pose[0] data들을 다음 marginalization factor로 넘긴다.
Non-Keyframe : Sliding에서 i=WINDOW_SIZE-1의 para_Pose, para_SpeedBias를 i=WINDOW_SIZE에 저장함으로써 constarint를 연결한다. (i=WINDOW_SIZE - 1)은 Sliding과정에서 삭제된다. address를 사용하는 이 과정으로,
(1) 이전에 Sliding으로 사라졌던 data들을 다음 optimiztion에 전달하여 jacobian, residual 계산에 사용되고
(2) MarginalizationFactor parameter blocks의 address는 계속 유지됨으로써, 매우 효율적으로 코드가 실행된다.
결국 marginalizationFactor로 수행하는 것은, 이전에 drop_set에서 out되어 계산되지 않던 data를 이 factor에서나마 jacobian, residual 계산에 dx로 포함시켜 linearize하는 것.
-
MarginalizationFactor에 last_marginalization_info를 저장. 논문의 cost function 수행
1) MarginalizationFactor
MarginalizationFactor::MarginalizationFactor(MarginalizationInfo* _marginalization_info):marginalization_info(_marginalization_info)
{
int cnt = 0;
for (auto it : marginalization_info->keep_block_size)
{
mutable_parameter_block_sizes()->push_back(it);
cnt += it;
}
set_num_residuals(marginalization_info->n);
};
bool MarginalizationFactor::Evaluate(double const *const *parameters, double *residuals, double **jacobians) const
{
int n = marginalization_info->n;
int m = marginalization_info->m;
Eigen::VectorXd dx(n);
for (int i = 0; i < static_cast<int>(marginalization_info->keep_block_size.size()); i++)
{
int size = marginalization_info->keep_block_size[i];
int idx = marginalization_info->keep_block_idx[i] - m;
Eigen::VectorXd x = Eigen::Map<const Eigen::VectorXd>(parameters[i], size);
Eigen::VectorXd x0 = Eigen::Map<const Eigen::VectorXd>(marginalization_info->keep_block_data[i], size);
if (size != 7)
dx.segment(idx, size) = x - x0;
else
{
dx.segment<3>(idx + 0) = x.head<3>() - x0.head<3>();
dx.segment<3>(idx + 3) = 2.0 * Utility::positify(Eigen::Quaterniond(x0(6), x0(3), x0(4), x0(5)).inverse() * Eigen::Quaterniond(x(6), x(3), x(4), x(5))).vec();
if (!((Eigen::Quaterniond(x0(6), x0(3), x0(4), x0(5)).inverse() * Eigen::Quaterniond(x(6), x(3), x(4), x(5))).w() >= 0))
{
dx.segment<3>(idx + 3) = 2.0 * -Utility::positify(Eigen::Quaterniond(x0(6), x0(3), x0(4), x0(5)).inverse() * Eigen::Quaterniond(x(6), x(3), x(4), x(5))).vec();
}
}
}
Eigen::Map<Eigen::VectorXd>(residuals, n) = marginalization_info->linearized_residuals + marginalization_info->linearized_jacobians * dx; // residuals의 index n부분에 대입.
if (jacobians)
{
for (int i = 0; i < static_cast<int>(marginalization_info->keep_block_size.size()); i++)
{
if (jacobians[i])
{
int size = marginalization_info->keep_block_size[i], local_size = marginalization_info->localSize(size);
int idx = marginalization_info->keep_block_idx[i] - m;
Eigen::Map<Eigen::Matrix<double, Eigen::Dynamic, Eigen::Dynamic, Eigen::RowMajor>> jacobian(jacobians[i], n, size); // (pointer object, index, size)
jacobian.setZero();
jacobian.leftCols(local_size) = marginalization_info->linearized_jacobians.middleCols(idx, local_size);
}
}
}
return true;
}
- marginalization_factor에는 marginalization_info 포인터와, residual의 개수가 들어있다.
- \(x_r\) 기존에 계산해둔 jacobain을 불러온다.
- localSize하는 이유는 쿼터니언의 마지막 w값이 필요없기 때문 (overParameterization을 줄이는 것과 비슷)
-
dx는 이전에 addr_shift에서 데이터를 옮겨주므로, para_Pose를 예시로 들면
para_Pose[0] - para_Pose[1] (data기준, size추출)이 된다. 따라서, 다음 수식이
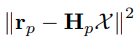
코드와 같음을 알 수 있다.
2)ResidualBlockInfo
void ResidualBlockInfo::Evaluate()
{
residuals.resize(cost_function->num_residuals());
std::vector<int> block_sizes = cost_function->parameter_block_sizes();
raw_jacobians = new double *[block_sizes.size()];
jacobians.resize(block_sizes.size());
for (int i = 0; i < static_cast<int>(block_sizes.size()); i++)
{
jacobians[i].resize(cost_function->num_residuals(), block_sizes[i]);
raw_jacobians[i] = jacobians[i].data();
}
cost_function->Evaluate(parameter_blocks.data(), residuals.data(), raw_jacobians);
if (loss_function)
{
double residual_scaling_, alpha_sq_norm_;
double sq_norm, rho[3];
sq_norm = residuals.squaredNorm();
loss_function->Evaluate(sq_norm, rho);
//printf("sq_norm: %f, rho[0]: %f, rho[1]: %f, rho[2]: %f\n", sq_norm, rho[0], rho[1], rho[2]);
double sqrt_rho1_ = sqrt(rho[1]);
if ((sq_norm == 0.0) || (rho[2] <= 0.0))
{
residual_scaling_ = sqrt_rho1_;
alpha_sq_norm_ = 0.0;
}
else
{
const double D = 1.0 + 2.0 * sq_norm * rho[2] / rho[1];
const double alpha = 1.0 - sqrt(D);
residual_scaling_ = sqrt_rho1_ / (1 - alpha);
alpha_sq_norm_ = alpha / sq_norm;
}
for (int i = 0; i < static_cast<int>(parameter_blocks.size()); i++)
{
jacobians[i] = sqrt_rho1_ * (jacobians[i] - alpha_sq_norm_ * residuals * (residuals.transpose() * jacobians[i]));
}
residuals *= residual_scaling_;
}
}
...
int localSize(int size)
{
return size == 7 ? 6 : size;
}
- raw_jacobian으로 각 parameter에 대해 jacobian을 만든다.
-
cost_function->Evaluate 에서는 각 factor들에 대한 Evaluate로 residual, jacobian을 계산한다.
loss function까지 적용된다. (Only for visual)
-
loss function → evaluate는 다음을 계산한다.
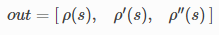
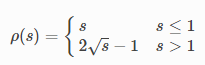
이때 사진의 out이 code에서의 rho가 된다.
-
Huber Loss에 대해 rho[2] 는 항상 ≤ 0 이므로 residual_scaling_ = 1,
s>1인 경우 (outlier일 만큼 residual이 큰 경우) \(s^{-1/4}\)가 된다. alpha_sq_norm_ = 0.
SUMMARY : Jacobian과 1보다 큰 residual에 \(\sqrt{\rho'(s)}\) 를 곱해준다. 이를 통해, 그전에 거르지 못한 outlier의 weight를 줄이는 효과를 추가적으로 가져온다.
Ceres 홈페이지 설명을 참조하면 :
If we didn’t do anything special the residual for the erroneous measurement will result in the entire solution getting pulled away from the optimum to reduce the large error that would otherwise be attributed to the wrong measurement.
Using a robust loss function, the cost for large residuals is reduced. In the example above, this leads to outlier terms getting down-weighted so they do not overly influence the final solution
[reference] : http://ceres-solver.org/nnls_modeling.html#lossfunction
3) MarginalizationInfo
void MarginalizationInfo::addResidualBlockInfo(ResidualBlockInfo *residual_block_info)
{
factors.emplace_back(residual_block_info);
std::vector<double *> ¶meter_blocks = residual_block_info->parameter_blocks;
std::vector<int> parameter_block_sizes = residual_block_info->cost_function->parameter_block_sizes();
for (int i = 0; i < static_cast<int>(residual_block_info->parameter_blocks.size()); i++)
{
double *addr = parameter_blocks[i];
int size = parameter_block_sizes[i];
parameter_block_size[reinterpret_cast<long>(addr)] = size;
}
for (int i = 0; i < static_cast<int>(residual_block_info->drop_set.size()); i++)
{
double *addr = parameter_blocks[residual_block_info->drop_set[i]];
parameter_block_idx[reinterpret_cast<long>(addr)] = 0;
}
}
void MarginalizationInfo::preMarginalize()
{
for (auto it : factors)
{
it->Evaluate();
std::vector<int> block_sizes = it->cost_function->parameter_block_sizes();
for (int i = 0; i < static_cast<int>(block_sizes.size()); i++)
{
long addr = reinterpret_cast<long>(it->parameter_blocks[i]);
int size = block_sizes[i];
if (parameter_block_data.find(addr) == parameter_block_data.end())
{
double *data = new double[size];
memcpy(data, it->parameter_blocks[i], sizeof(double) * size);
parameter_block_data[addr] = data;
}
}
}
}
int MarginalizationInfo::localSize(int size) const
{
return size == 7 ? 6 : size;
}
int MarginalizationInfo::globalSize(int size) const
{
return size == 6 ? 7 : size;
}
std::vector<double *> MarginalizationInfo::getParameterBlocks(std::unordered_map<long, double *> &addr_shift)
{
std::vector<double *> keep_block_addr;
keep_block_size.clear();
keep_block_idx.clear();
keep_block_data.clear();
for (const auto &it : parameter_block_idx)
{
if (it.second >= m)
{
keep_block_size.push_back(parameter_block_size[it.first]);
keep_block_idx.push_back(parameter_block_idx[it.first]);
keep_block_data.push_back(parameter_block_data[it.first]);
keep_block_addr.push_back(addr_shift[it.first]);
}
}
sum_block_size = std::accumulate(std::begin(keep_block_size), std::end(keep_block_size), 0);
return keep_block_addr;
}
- MarginalizationInfo class는 생성시에 valid = true를 지정하는 것 이외에 딱히 해주는 것은 없다.
- addResidualBlockInfo 함수에서, residual_block_info의 parameter, 그리고 그 각각의 size를 가져온다.
-
address기반 map 정리 (jacobian,residual 중첩 계산을 위해 address 사용)
parameter_block_size : 각 parameter block의 size (6,9 등)
parameter_block_idx : 각 parameter block의 index in A,b
parameter_block_data : 각 parameter block의 data를 복사해둠 - preMarginalize함수에서, 각 factor의 jacobian, residual을 구한다. 또한 모든 parameter들의 data를 parameter_block_data map에 저장한다.
-
getParameterBlocks에서는, slidingWindow작업을 미리 해둔 addr_shift를 사용하여MarginalizationInfo를 위한 data를 만든다.
addr_shift에서 i의 address에 i-1 data를 넣고, it.second ≥ m 인 것만 keep_block으로 만듦으로써, para_Feature는 버리면서 i=0, …, WINDOW_SIZE-1까지의 IMU constraint를 다음 MarginalizationFactor로 넘기게 된다.
추가적으로 it.first는 address이므로 parameter들의 address는 Marginalization에 대해 계속동일하다.
4) void MarginalizationInfo::marginalize()
int pos = 0;
for (auto &it : parameter_block_idx) // drop_set에 대한것만 넣음
{
it.second = pos; // it.second는 이전까지의 size의 합이 된다.
pos += localSize(parameter_block_size[it.first]);
}
m = pos; // drop_set size들의 합.
for (const auto &it : parameter_block_size)
{
// drop_set아닌 것들에 대해서도 parameter_block_idx에 (addr, 이전까지 size의 합)
if (parameter_block_idx.find(it.first) == parameter_block_idx.end())
{
parameter_block_idx[it.first] = pos;
pos += localSize(it.second);
}
}
n = pos - m; // 비 drop_set size들의 합.
//ROS_INFO("marginalization, pos: %d, m: %d, n: %d, size: %d", pos, m, n, (int)parameter_block_idx.size());
if(m == 0)
{
valid = false;
printf("unstable tracking...\n");
return;
}
Eigen::MatrixXd A(pos, pos);
Eigen::VectorXd b(pos);
A.setZero();
b.setZero();
pthread_t tids[NUM_THREADS];
ThreadsStruct threadsstruct[NUM_THREADS];
int i = 0;
for (auto it : factors)
{
threadsstruct[i].sub_factors.push_back(it);
i++;
i = i % NUM_THREADS;
}
for (int i = 0; i < NUM_THREADS; i++)
{
TicToc zero_matrix;
threadsstruct[i].A = Eigen::MatrixXd::Zero(pos,pos);
threadsstruct[i].b = Eigen::VectorXd::Zero(pos);
threadsstruct[i].parameter_block_size = parameter_block_size;
threadsstruct[i].parameter_block_idx = parameter_block_idx;
int ret = pthread_create( &tids[i], NULL, ThreadsConstructA ,(void*)&(threadsstruct[i]));
if (ret != 0)
{
ROS_WARN("pthread_create error");
ROS_BREAK();
}
}
for( int i = NUM_THREADS - 1; i >= 0; i--)
{
pthread_join( tids[i], NULL );
A += threadsstruct[i].A;
b += threadsstruct[i].b;
}
//이미 symmetric하지만 더 확실하게 (?)
Eigen::MatrixXd Amm = 0.5 * (A.block(0, 0, m, m) + A.block(0, 0, m, m).transpose());
Eigen::SelfAdjointEigenSolver<Eigen::MatrixXd> saes(Amm);
Eigen::MatrixXd Amm_inv = saes.eigenvectors() * Eigen::VectorXd((saes.eigenvalues().array() > eps).select(saes.eigenvalues().array().inverse(), 0)).asDiagonal() * saes.eigenvectors().transpose();
Eigen::VectorXd bmm = b.segment(0, m);
Eigen::MatrixXd Amr = A.block(0, m, m, n);
Eigen::MatrixXd Arm = A.block(m, 0, n, m);
Eigen::MatrixXd Arr = A.block(m, m, n, n);
Eigen::VectorXd brr = b.segment(m, n);
A = Arr - Arm * Amm_inv * Amr;
b = brr - Arm * Amm_inv * bmm;
Eigen::SelfAdjointEigenSolver<Eigen::MatrixXd> saes2(A);
Eigen::VectorXd S = Eigen::VectorXd((saes2.eigenvalues().array() > eps).select(saes2.eigenvalues().array(), 0));
Eigen::VectorXd S_inv = Eigen::VectorXd((saes2.eigenvalues().array() > eps).select(saes2.eigenvalues().array().inverse(), 0));
Eigen::VectorXd S_sqrt = S.cwiseSqrt();
Eigen::VectorXd S_inv_sqrt = S_inv.cwiseSqrt();
linearized_jacobians = S_sqrt.asDiagonal() * saes2.eigenvectors().transpose();
linearized_residuals = S_inv_sqrt.asDiagonal() * saes2.eigenvectors().transpose() * b;
- Thread마다 갖고있는 ThreadsStruct 에 factor들을 나눠서 담아서 ThreadsConstructA 함수를 각각 실행한다. 이후 각 A와 b를 합친다.
-
식 (43)과 같이 H = A를 정리하면
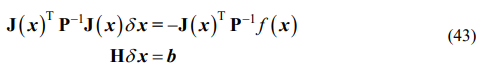
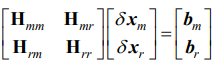
여기서 m은 marginalize off할 것들(버릴 것들), r은 유지할 정보들(나머지)을 의미한다. Schur complement를 통해 다음과 같이 식을 바꿀 수 있고,
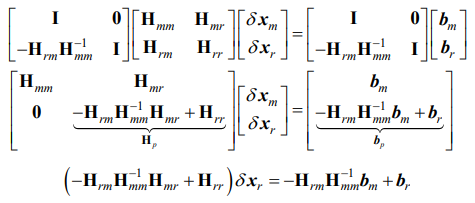
이를통해, MarginalizationFactor에서 사용될 linearized_jacobians, linearized_residuals 를 구한다. marginalzation에 사용되는 state는 index ≥ m 이므로 \(x_r\)에 대한 jacobian과 residual이 구해진다. (MarginalizationInfo::getParameterBlocks 함수 참고.)
- Marginalization은 다음과 같이 p(x,y)를 p(x)로 바꾸는 과정에서 유래된 것으로, SLAM에서는 marginalization을 통해 old states를 remove한다.
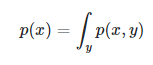
[reference1] : https://www.programmersought.com/article/77613780997/
[reference2] : https://robotics.stackexchange.com/questions/8900/slam-why-is-marginalization-the-same-as-schurs-complement
최종적으로, marginalization factor로 전환되어 ceres에서 optimization에 사용된다.
5) void* ThreadsConstructA(void* threadsstruct)
ThreadsStruct* p = ((ThreadsStruct*)threadsstruct);
for (auto it : p->sub_factors)
{
for (int i = 0; i < static_cast<int>(it->parameter_blocks.size()); i++)
{
int idx_i = p->parameter_block_idx[reinterpret_cast<long>(it->parameter_blocks[i])];
int size_i = p->parameter_block_size[reinterpret_cast<long>(it->parameter_blocks[i])];
if (size_i == 7)
size_i = 6;
Eigen::MatrixXd jacobian_i = it->jacobians[i].leftCols(size_i);
for (int j = i; j < static_cast<int>(it->parameter_blocks.size()); j++)
{
int idx_j = p->parameter_block_idx[reinterpret_cast<long>(it->parameter_blocks[j])];
int size_j = p->parameter_block_size[reinterpret_cast<long>(it->parameter_blocks[j])];
if (size_j == 7)
size_j = 6;
Eigen::MatrixXd jacobian_j = it->jacobians[j].leftCols(size_j);
if (i == j)
p->A.block(idx_i, idx_j, size_i, size_j) += jacobian_i.transpose() * jacobian_j;
else
{
p->A.block(idx_i, idx_j, size_i, size_j) += jacobian_i.transpose() * jacobian_j;
p->A.block(idx_j, idx_i, size_j, size_i) = p->A.block(idx_i, idx_j, size_i, size_j).transpose();
}
}
p->b.segment(idx_i, size_i) += jacobian_i.transpose() * it->residuals;
}
}
return threadsstruct;
- 변수 이름과 같이 p→parameter_block_idx는 인덱스, p→parameter_block_size는 각 parameter block의 사이즈이다.
-
i는 row, j는 col에 해당하며, (i,j)에서 size_i, size_j에 대해 A와 b를 계산한다.
다음식 (43)에 의해 state estimation을 위해 H = A, b를 만들어준다.
- 흥미로운 것은, idx_i, idx_j 가 address기준으로 정해지기 때문에, 해당 (idx_i, idx_j)에 해당하는 부분의 A에 factors의 \(J^TP^{-1}J\) 값이 합쳐져서 더해진다는 것이다.
- -(minus)를 안 붙이는 것은 Mahalanobis norm에서 제곱되기 때문에 무시한것으로 보인다.
VINS-Fusion 코드를 정리한 포스트입니다.
- VINS-Fusion Code Review - (1) Image Processing
- VINS-Fusion Code Review - (2) IMU Processing
- VINS-Fusion Code Review - (3) Initialization
- VINS-Fusion Code Review - (4) Sliding window & Optimization
- VINS-Fusion Code Review - (5) Marginalization
- VINS-Fusion Code Review - (6) Graph optimization
Reference
- [2017] Quaternion kinematics for the error-state Kalman filter.pdf
- [2005] Indirect Kalman Filter for 3D Attitude Estimation.pdf
- Formula Derivation and Analysis of the VINS-Mono.pdf
- Marginalization&Shcurcomplement.pptx
- [TRO2012] Visual-Inertial-Aided Navigation for High-Dynamic Motion in Built Environments Without Initial Conditions.pdf
- VINS-Mono.pdf